

この記事で紹介している製品
おことわり
この記事は、2021年4月にQiitaに投稿した記事を加筆修正したものです。
また、この記事のオリジナルは日本語で書かれています。記事が日本語以外の言語で表示されている場合、それは機械翻訳の結果です。当社は機械翻訳の精度に責任を負いません。
はじめに
前回のPower Loss Protection (PLP)に続き、SSDの製品仕様書に記載されている機能のうち
- 内容があまりよく知られていない機能
- 名前が似ていても内容が異なる機能
- そもそも明確に規定されておらずメーカーにより内容が異なる機能
に該当する、End-to-End Data ProtectionとEnd-to-End Data Path Protectionを説明します。1語(Path)の有無で大きな違いがあります。
なお、この記事では以降読みやすさのために表1の用語を使用します。
| 略語 | 意味 |
|---|---|
| E2Eデータ保護 | End-to-End Data Protectionのこと |
| E2Eデータパス保護 | End-to-End Data Path Protectionのこと |
| E2E機能 | E2Eデータ保護とE2Eデータパス保護の両方をまとめたもの |
まとめ
- E2Eデータ保護とE2Eデータパス保護はどちらも、発生するエラーからデータを保護してデータインテグリティを保証する機能だが、保護範囲が異なる
- E2Eデータ保護は標準化された機能だが、E2Eデータパス保護は標準化された機能ではない
- E2Eデータ保護はホストとストレージ両方の対応が必要だが、E2Eデータパス保護はストレージだけの対応で良い
概要
E2E機能は、ストレージのデータインテグリティ(無理やり和訳すると「データの整合性・一貫性」)を保証する機能です。
「データインテグリティ」とは、言いかえれば「ホストから書き込まれたデータをホストから正しく読み出せること」であり、ストレージの最も重要な機能(というか要件)です。
この機能に支障をおよぼすエラーへの対策には、原因にあわせて様々な方法があり実際に適用されていて、E2E機能もそのひとつです。
具体的な仕組みの説明に入る前に、この保護機能について、保護可能範囲、使用されるシステム、そしてメリットとデメリット、を説明します。
保護可能範囲
E2Eデータ保護とE2Eデータパス保護は保護可能範囲が異なります。これを示したものが図1です。
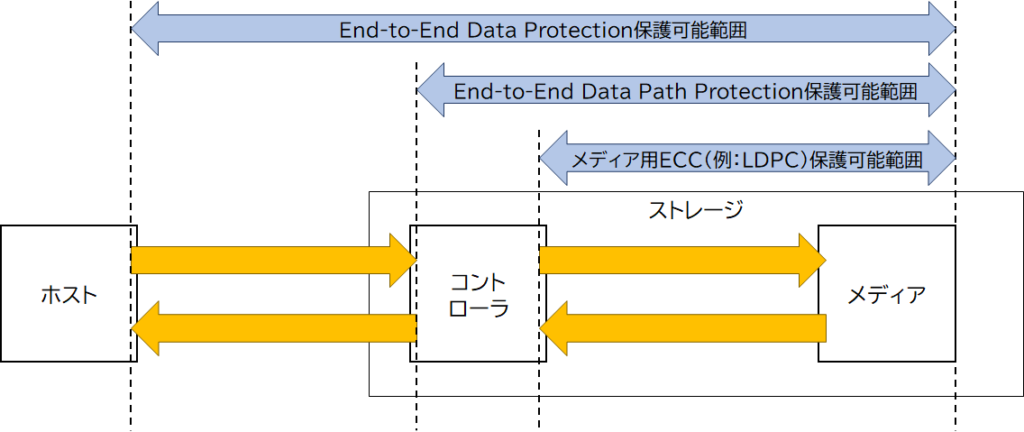
図1の通り、E2Eデータ保護はホスト・ストレージ間の通信経路も保護可能な機能ですが、E2Eデータパス保護はストレージ内のみを保護可能範囲とする機能です。
保護可能範囲が異なるということは、「機能名内の“End”の指す位置が異なる」と言いかえることができます。そこで、E2E機能それぞれの“End”がどこか(どの位置を指すのか)を示したものが表2です。
| End | to | End | |
|---|---|---|---|
| E2Eデータ保護 (End-to-End Data Protection) | ホスト・ストレージ間のパスのホスト側の端 | to | メディア |
| E2Eデータパス保護 (End-to-End Data Path Protection) | ホスト・ストレージ間のパスのストレージ側の端 | to | メディア |
図1と比較するとわかりやすいと思います。これが保護可能範囲の違いです。
E2Eデータ保護は主にSCSI(SAS含む)ストレージで使われてきました。SCSIはパラレルインターフェースであり、用途や使いかたによってはホスト・ストレージ間でのデータ化けが無視できない場面もありました。そのため、ホスト・ストレージ間も保護可能範囲に含んでいます。
一方E2Eデータパス保護は、ストレージ内でメディア向け誤り訂正符号では保護できない部分(主にコントローラ)を保護可能範囲に入れた機能だと言えます。
使われるシステム
E2データ保護とE2Eデータパス保護は使われるシステムが異なります。
E2Eデータ保護は、扱うデータの一貫性に非常に高い信頼性が求められるエンタープライズシステムで用いられます。金融システム(例:取引等トランザクションの保存)用ストレージや、政府・企業等の基幹サーバ・データベース用ストレージなどがその例です。
それらのシステムでは、要因を問わずストレージから読み出したデータの間違いが大きな損害・障害につながるため、E2Eデータ保護を用いてホスト・ストレージ間のパスも保護し、データインテグリティの保証をより確実にします。
E2Eデータ保護はストレージ側だけでなくホスト側の対応も必要な機能であり、上記のようなシステムではE2Eデータ保護に対応したホスト側機器およびソフトウェアが使われます。
一方E2Eデータパス保護は、最近ではコンシューマ向けSSDのコントローラでも対応しています。この結果、コンシューマ向け機器をはじめとした幅広いシステムで使われています。
E2Eデータパス保護は、SSDコントローラの製造プロセス微細化し、SSDコントローラ内で発生するエラーへの対応が重要視されるにしたがい実装されはじめた機能です。
私が知る限り、E2Eデータパス保護のほうが後から登場した機能です。そのため、既存のE2Eデータ保護と区別するために“Path”という1語を追加したのだと思います。
メリットとデメリット
E2Eデータ保護とE2Eデータパス保護それぞれのメリットとデメリットはほぼ表裏一体です。
E2E機能のメリットとデメリットをまとめると表3のようになります。
| E2Eデータ保護 (End-to-End Data Protection) | E2Eデータパス保護 (End-to-End Data Path Protection) | |
|---|---|---|
| メリット | ・ホストストレージ間も保護可能 ・機能が標準化されている | ・ホスト側は対応不要(ストレージ内で完結) ・ホストインターフェースに依存しない ・対応製品は多い |
| デメリット | ・ホストとホストインターフェースで要対応 ・対応製品が少なく高価 | ・ホストストレージ間は保護可能範囲外 ・機能が標準化されていない |
E2Eデータ保護は保護可能範囲が広い代わりにホストとホストインターフェースの対応も必要で、対応製品も少ないです。
E2Eデータ保護に対応したホストインターフェースはSCSI (SAS)、NVMe程度に限られるため、対応SSDはSAS SSDやハイエンドNVMe SSDの一部などに限られています[1][2]。
一方、E2Eデータパス保護は保護可能範囲がストレージ内にとどまりますがその分ホストの対応は不要で対応製品も最近は多いです。
その他には、E2Eデータ保護は機能が標準化されているのに対し、E2Eデータパス保護は機能が標準化されていないことが挙げられます。
したがって、E2Eデータパス保護は、その機能や実現方法がメーカーによって異なる可能性があります。
保護の仕組み
それではE2E機能の具体的な内容についてご説明します。
この機能が保護するエラー
まず、E2E機能が保護するエラーを説明します。
なお、ここで説明するエラーはあくまでも例です。そして、これらのエラーに対してはSRAMやDRAMの誤り訂正機構をはじめ様々な対策方法が存在し、メーカーは求められる信頼性を満足するよう、使用する部品などに応じて対策を入れて、製品を設計・開発していることをあらかじめ記載しておきます。
ホストがストレージにデータを書きこむとき、ストレージは図2のような処理を行います。
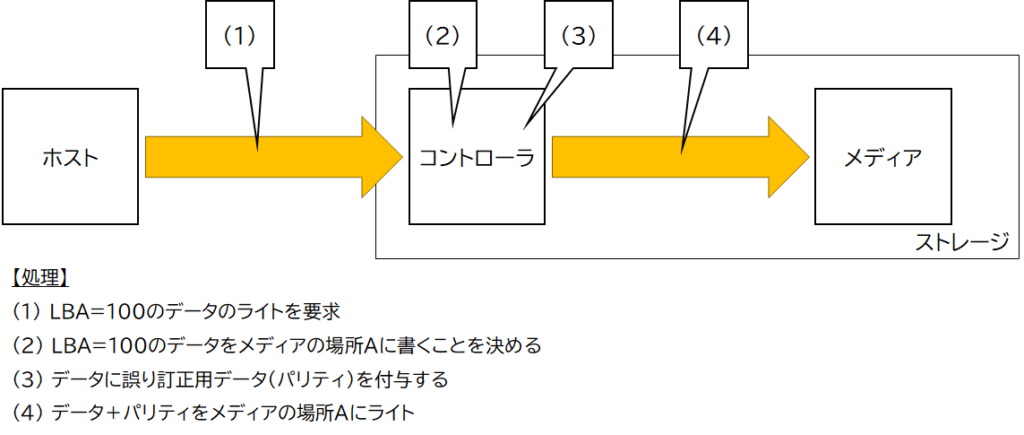
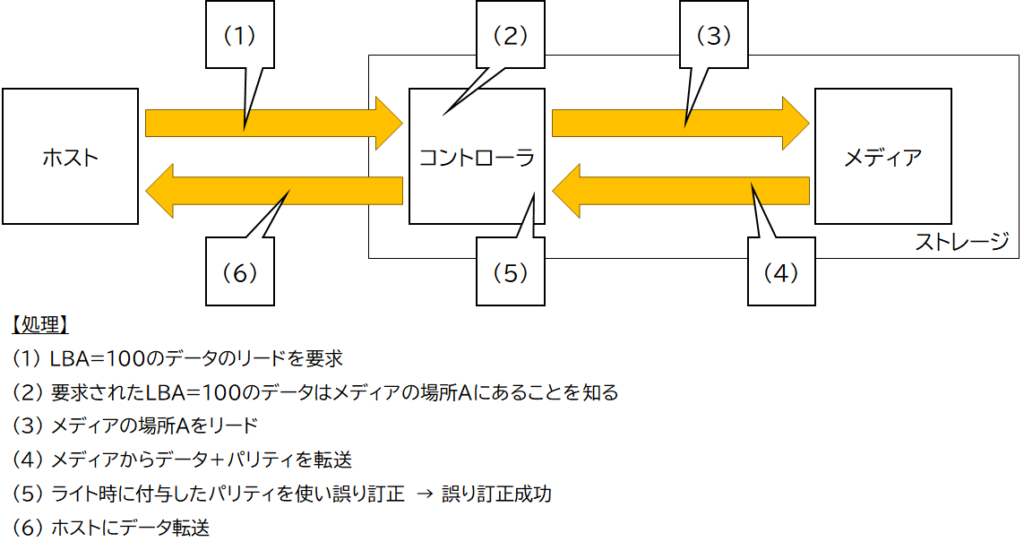
そして、書き込んだデータをホストが読み出すとき、ストレージは図3のような処理を行います。
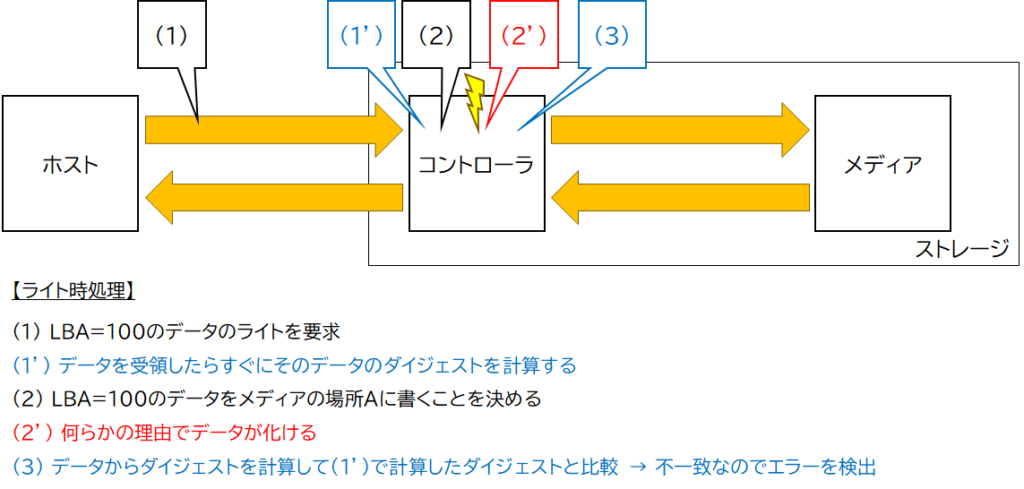
ここで、ライト時にコントローラ内で何らかの理由でデータが化けたとします。すると、図2で示した処理は図4のようになる可能性があります。
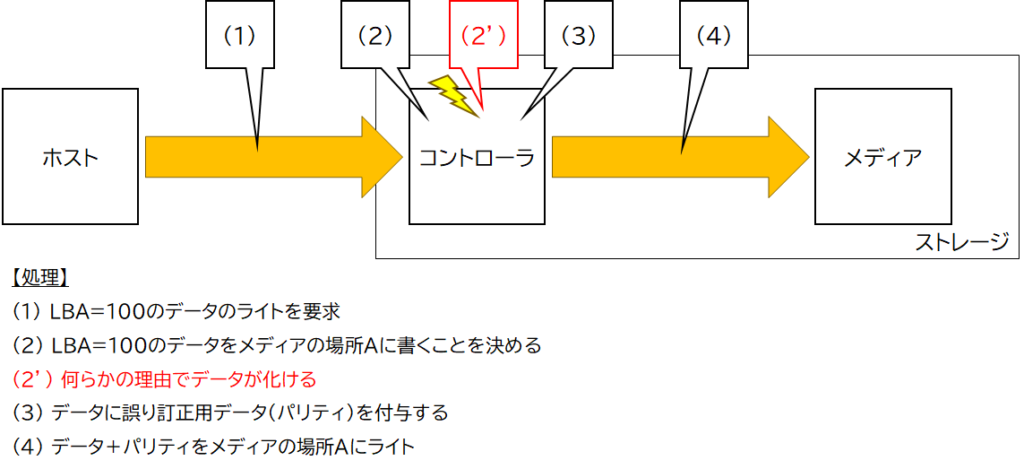
図4のエラー発生位置はあくまで例です。とにかく図4 (3)の処理の前にエラー(データ化け)が発生してそのエラーが放置されたという想定です。
図4のようにメディア(例えばNANDフラッシュメモリ)でのエラーを検出・訂正するための誤り訂正用データ(パリティ)を作成する前にデータが化けてしまうと、化けたデータからパリティを生成してしまいます。つまり、図4の(4)でメディアにライトされるのは、化けたデータと、化けたデータ用に作成されたパリティ、になります。
このため、図4の書き込みの後に図3の読み出し処理をした場合、図3 (5)の誤り訂正処理は図4 (2′)で生じたエラーを訂正できません。その結果、図3 (5)の誤り訂正処理で訂正に成功しても訂正結果は「化けたデータ」であり、ストレージからホストへ転送されたデータは「化けたデータ」となります。
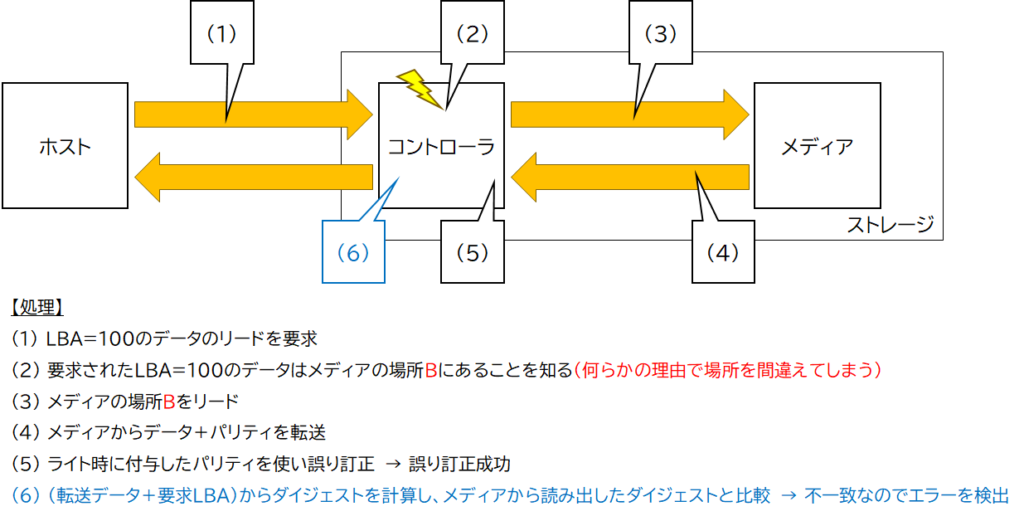
「ホストから書き込まれたデータをホストから正しく読み出せること」が満たされないケースは、図4のケース以外に図5のようなケースも考えられます。
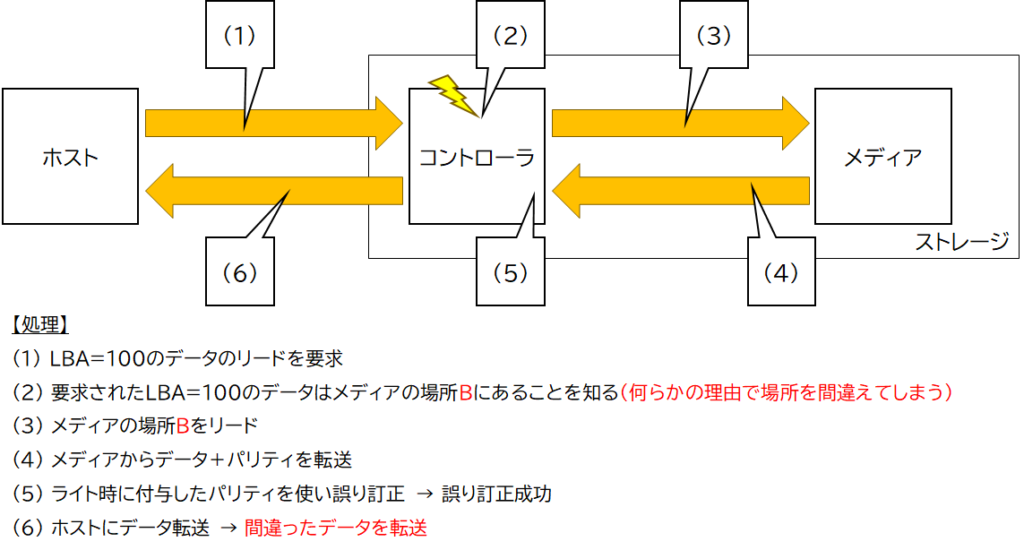
コントローラでは、ホストから要求されたデータ(最新データ)が記録されているメディア上の位置を調べ、判明した場所からデータを読み出します。この「メディア上の位置」を調べる際に何らかの理由で異なる場所だと判断してしまう可能性があります。
すると、その「間違った場所」から読み出したデータをホストへ転送してしまいます。
この図4や図5のようなエラーにより「ホストに間違ったデータを返してしまうこと」を防ぐ方法のひとつがE2E機能です。エラーの発生を防ぐのではなくエラーが発生しても検出可能にするということがポイントです。
E2Eデータ保護(End-to-End Data Protection)とは
E2Eデータ保護は、ホストとストレージが協力して上記のようなエラーに対応する方法です。
というのも、E2Eデータ保護はホストが別途作成した付加データ(メタデータ)を用いる方法だからです。具体的には、図6のような動作になります。
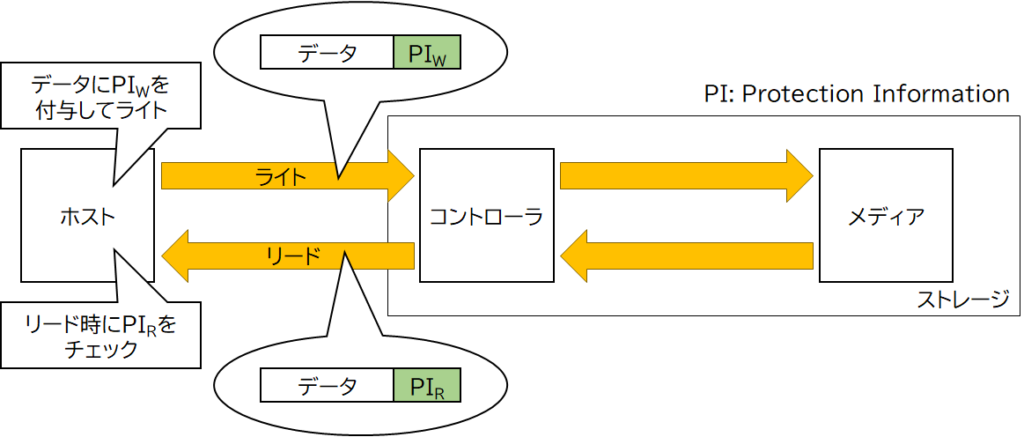
ホストは、ストレージにデータをライトする際に、データ(512バイトや4096バイト)に対応したProtection Information (PI)と呼ばれるメタデータをストレージに送ります。そして、ストレージからデータをリードする際に、ライト時に送ったメタデータも受領し、そのメタデータが正しいこと(例:ライト時のメタデータと一致すること)を検査することで受領したデータが正しいことを確認する、という仕組みです。
このProtection Informationの内容は、仕様で表4のように規定されています[3][4]。
| 名称 | サイズ | 内容 |
|---|---|---|
| Guard | 2バイト | データ部分から計算したCRC16 |
| Application Tag | 2バイト | ホスト(Host Bus Adapter (HBA)を含む)が自由に使えるフィールド |
| Reference Tag | 4バイト | データに対応するLBA (Logical Block Address)相当の値 |
E2Eデータ保護という名称はNVMe仕様で使われているものですが、その機能はSCSIの機能をベースにしています。これは、NVMeの仕様がSCSIの影響を大きく受けており、SCSIのProtection Informationの仕様をほぼそのまま取り込んだ結果です。
エラー検出の仕組み
このProtection Informationを使うことで、図4や図5で示したエラーを検出できます。
まず、図4で示した現象のように、何らかの理由で化けたデータがメディアに書き込まれてしまい、リード時にそのデータが読み出されてホストに転送された場合です。
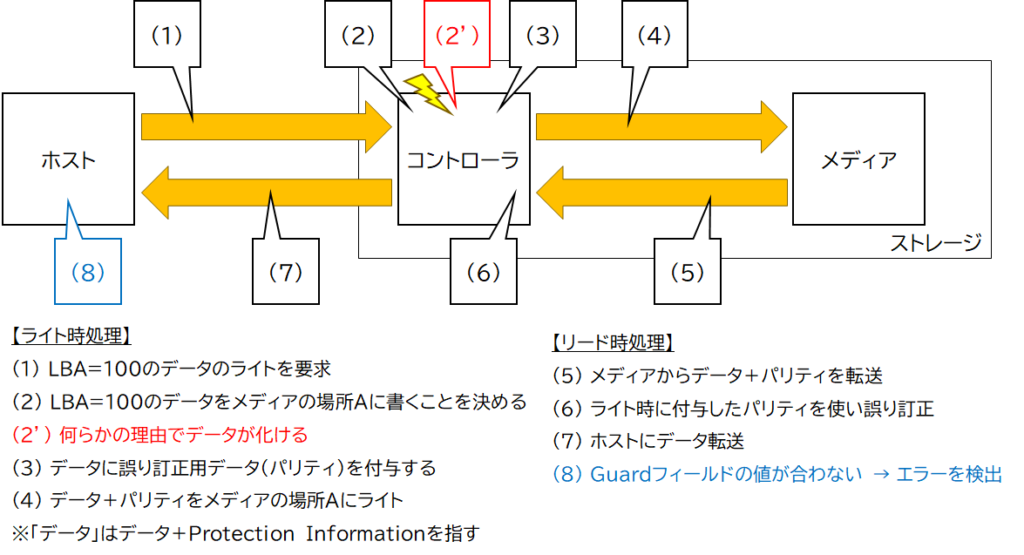
この場合、図7のように、ストレージからデータ(化けたデータ)を受領したホストが、受領したデータ(Protection Informationを除く)から計算したCRC16の値と、Protection Information内のGuardフィールドの値を比較することで、データが化けているかどうかを検査できます(図7 (8))。
次に、図5で示した現象のように、何らかの理由でストレージがホストの要求したLBAではないLBAのデータを読み出してホストに転送した場合です。
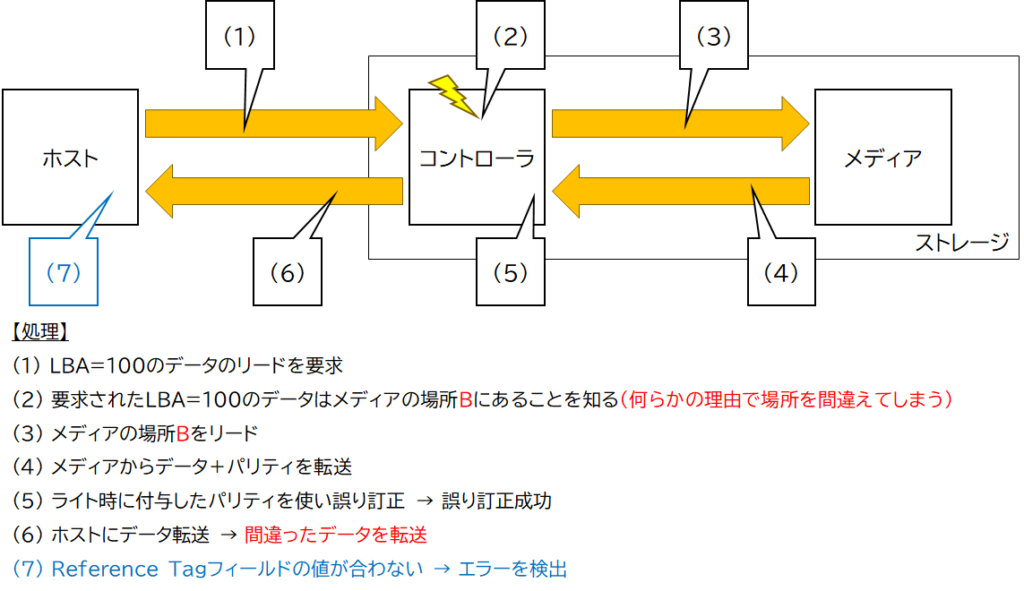
この場合、図8のように、ストレージからデータ(要求したLBAとは異なるLBAのデータ)を受領したホストが、自分がデータを要求したLBAと受領したデータのProtection Information内のReference Tagフィールドの値を比較することで、データが取り違えられていないかどうかを検査できます(図8 (7))。
このように、Protection Informationを使用することで、ストレージ内で発生し得るいくつかのエラーを検出できます。
なお、ここでは省略しますが、このProtection Informationを利用してストレージ内でエラーチェックを行う方法もあります。ストレージ内でこまめにエラーチェックを行うと、エラー発生場所の絞り込みが可能になります。
ストレージが対応しているか判断する方法
ストレージがこのE2Eデータ保護に対応しているかどうかをスペック(仕様)で判断するには、Protection Informationへの対応が記載されているか、“T10 DIF”や“DIX”への対応が記載されているか、そして520バイトや4104バイトなどのセクタ長に対応しているか、などの方法があります。
DIF (Data Integrity Field)とDIX (Data Integrity eXtensions)はどちらも、ホストがProtection Informationを作成してストレージに送る方法、そしてストレージから受け取ったProtection Informationをチェックする方法です[5]。したがって、ストレージがDIFもしくはDIXに対応していれば、そのストレージがE2Eデータ保護に対応していると言えます。
520バイトや4104バイトというセクタ長は、実は「512バイト+8バイト」や「4096バイト+8バイト」のことを指し、この「8バイト」がProtection Informationのことを意味します。つまり、ストレージがこの520バイトや4104バイトなどの中途半端なセクタ長をサポートしていたら、それはProtection Informationのサポートを意味し、E2Eデータ保護のサポートを意味します。なお、520バイトや4104バイトの他にも、528バイト(512バイト+8バイト+8バイト)や4112バイト(4096バイト+8バイト+8バイト)などのバリエーションもあります。
E2Eデータパス保護(End-to-End Data Path Protection)とは
E2Eデータパス保護はストレージに閉じた仕組みで、前半に説明した通り標準化された機能ではありません。
つまり、SSDのカタログ(仕様)に「E2Eデータパス保護対応」と書かれていても、メーカーごとに機能(何ができるのか)や実現方法(仕組み)が異なる可能性があります。
したがって、ここで「E2Eデータパス保護とは~~という動作です」とは説明できません。
エラー検出の仕組み
「E2Eデータパス保護とは~~という動作です」とは説明できませんが、図4や図5で示したエラーを検出するための仕組みとしてのE2Eデータパス保護の例を説明します。
それは、Protection InformationのGuardフィールドのようにデータから計算したダイジェスト(CRCなど)を使う方法です。
まず、図4で示した現象のように、コントローラ内で何らかの理由で化けたデータがメディアに書き込まれそうになった場合です。
この場合、図9のように、ストレージは、ホストからデータを受領するとすぐにそのデータ(化けていないデータ)からダイジェスト(CRCなど)を計算します(図9 (1′))。
そして、少なくともメディア(例:NANDフラッシュメモリ)のエラーに対応するための誤り訂正用データ(パリティ)を計算する直前に、パリティの計算に使用するデータから再度ダイジェストを計算し(図9 (3))、ホストからデータを受領した時に計算したダイジェスト(図9 (1′))と比較します。何らかの理由でデータ化けが発生した場合(図9 (2′))はこの2つのダイジェストが一致しないので、データ化けを検出できます。
次に、図5で示した現象のように、何らかの理由でストレージがホストの要求したLBAではないLBAのデータを読み出した場合です。
この場合、図10のように、読み出したデータをホストに転送する直前(コントローラから離れる直前)に、転送しようとしているデータのダイジェストを計算します(図10 (6))。この時、ホストから要求されたLBAをダイジェストの計算対象に加えます。図9 (1′)でデータライト時にダイジェストを計算する際に同じくホストから指示されたLBAを計算対象に加えておくことで、図10 (6)でダイジェストが一致しない場合、LBAの不一致つまりデータの取り違えが発生した可能性を検出できます。
E2データパス保護の機能と実現方法としては、このようなE2データパス保護と似た機能と実現方法が考えられます。
いずれにしても、E2Eデータパス保護は標準化された機能ではなく、メーカーごとに機能や仕組みが異なる可能性があるため、機能の内容や仕組みをメーカーに確認する必要があります。
おわりに
今回は、SSDのスペック(仕様)に記載されていることがあるE2Eデータ保護(End-to-End Data Protection)とE2Eデータパス保護(End-to-End Data Path Protection)の違いを説明しました。
どちらの方法もストレージの信頼性(データインテグリティ)をより高いレベルで保証するための機能です。
一方で、保護可能範囲の違いや機能の標準化の有無をはじめとしたメリット・デメリットがあるため、利用にあたっては十分な検討が必要です。
References
[1] Seagate、「Nytro SAS SSDシリーズ」、2024年4月17日閲覧
[2] Kioxia、「PM6-Mシリーズ」、2024年4月17日閲覧
[3] T10, ``SCSI Block Commands – 3 (SBC-3)”, Revision 21, November 2009
[4] NVM Express, ``NVM ExpressTM Base Specification”, Revision 1.4b, September 2020
[5] Jim Williams and Martin Petersen, ``Data Integrity in the Storage Stack“[PDF], SNIA Storage Developer Conference 2008, Santa Clara, CA, September 2008
他社商標について
記事中には登録商標マークを明記しておりませんが、記事に掲載されている会社名および製品名等は一般に各社の商標または登録商標です。
記事内容について
この記事の内容は、発表当時の情報です。予告なく変更されることがありますので、あらかじめご了承ください。



